


Article 2: Protocol Learning, Protocol Models and the Great Convergence
Two enormous, previously disparate fields converge and a path towards the largest models to ever be trained is opened.


We discuss a new paradigm for large model training, Protocol Learning, where foundation models are trained and hosted in a trustless, decentralized manner with partial model ownership and governance. Implementing this paradigm requires the convergence of the two currently disjoint fields: Cryptography and AI. Protocol Learning opens a path towards potentially the largest models to ever be trained, introduces permissionless innovation dynamics to foundation model development, and provides a counterweight to the massive concentration of power forming at the model layer.
Decentralized training appears feasible. In this setting, nodes are geographically separated and communicate gradients and activations via low-bandwidth interconnects. There are numerous challenges in applying large-scale distributed training approaches to the noisy, dynamic, and communication-restricted setting. However, up to 1B parameter models have already been trained, there is growing researcher interest, several immediate research directions that have not been explored and 10B parameter runs are beginning. When implemented, decentralized training allows for creation of useful models via volunteer collaboration but provides no mechanism for value capture by model trainers. There is hence no incentive to participate beyond the current motivations of open source, which as of today has failed to produce foundation models. Protocol Learning subsumes volunteer based decentralized training and integrates a novel mechanism for model monetization, facilitating enormous training runs.
For decentralized foundation model training runs to occur, a very large amount of compute must be present. Llama3 400B was trained on 16k 80GB H100s; far beyond what is feasible in a volunteer setting. In order for large-scale decentralized training to be realized, incentives must be introduced to assemble the compute required within the training protocol.
Protocol Learning introduces such incentives in the form of partial model ownership allocated proportional to training contribution. This ownership is a core technical property; it does not rely on contracts or external enforcement. Achieving this requires a significant departure from how models are currently trained and the introduction of a novel construct; neural networks that can be collaboratively trained, but who’s full weight set can never be extracted by any one actor. We term such networks, Protocol Models (PMs) and they form the core of Protocol Learning. PMs are critical as the value of a model is in the weights, and ownership (and hence value flow and hence incentives) cannot be guaranteed if the full weight set is ever exposed. PMs ensure that any one participant, or groups of participants, cannot obtain the complete model weights without spending more computational power than would be required to train the model.
Implementations of Protocol Learning are protocols that are:
Decentralized: Training nodes are geographically separated, both node memory and compute is heterogeneous, the swarm is elastic, and communication is via low-bandwidth connections.
Incentivized: Trainers are allocated partial model ownership implemented with Protocol Models. Value flows from model users back to model trainers proportional to their contribution. No one group can achieve total model control or obtain the full model weights.
Trustless: Up to a limit, bad actors are unable to derail training runs by providing malicious or incorrect gradients, and contributions to training that result in ownership allocation are verified.
This article describes the motivating factors for the Protocol Learning setting and the core properties of PMs. Protocol Learning opens the door to both creation and value capture at the foundation model layer by individuals and coalitions rather than large corporations and states. It provides a path to the rich, permissionless innovation that characterizes open source but as of yet is not present in foundation model development. It aligns incentives in such a way that large scale pools of compute, and hence large scale models can be created, facilitates true community governance, and provides a guarantee of public access to a technology that will profoundly impact society's political, cultural, and economic structures.
The open source AI misnomer
‘Releasing weights for free' has become equivalent to ‘open source' in the context of Foundation Models. Traditional open source development requires the donation of community time and expertise; foundation model training requires millions of dollars of real world expense. Hence while they have adopted the same name, the fundamental dynamics of these processes are completely different.
The current open source AI movement requires at least one megacorp (or state) to continue to release a competitive, and hugely costly, base model which can be cloned, adapted and integrated into other systems. Releasing the output of a process that requires hundreds of millions to billions of dollars in cost for free, without constraints, is unsustainable and will not continue as model training costs continue to increase. Releasing the weights of early models is a good strategy to drive adoption and developer mindshare, however at some point monetization must begin to provide a return for such entities. Additionally, while today the majority of models are trained on public data, as the shift to proprietary and private data continues, releasing weights comes with significant liability risk and provides such entities clear justification to move to closed weights. Once closed, there may be many forms of monetization aside from simply charging for model access, however the terminal state is that some value will be extracted from model consumers which, in aggregate, will be greater than the total cost to train.
Without the ability to create base foundation models, open source’s influence at the model layer is heavily limited. This lack of an open source ecosystem, in turn, results in a lack of community input on the behavior of such models. This alone is undesirable, however another major concern is guaranteed access. LLM’s today are primarily augmentative to knowledge work, and individuals without access would find themselves severely economically disadvantaged. A reasonable analogy would be internet access, in the case where internet access could be arbitrarily declined to many users. However, significantly more critical is access to the base models in the case when capabilities continue to increase. There is a risk that such powerful models would not be released to the general public. This has the potential to result in severe economic polarization. This path cannot be avoided without a competitive marketplace of foundation models, which seems unlikely given the economics of training lends the field towards oligopoly or monopoly.
Overcoming the compute limitation in open source model training is a core motivator of Protocol Learning.
Assembling a sufficiently large swarm requires incentives
An alternative to open source’s dependence on ongoing base model releases from megacorporations is for a group to acquire compute grants, train the model centrally and then release the weights. The most successful example of this is the BLOOM model, designed by a coalition of 1,000 researchers from over 70 countries and 250 institutions, leading to a final run of 117 days at a cost of approximately EUR 3M and a full open source release of all model artifacts. This approach suffers from several problems. Approval must be obtained from grant allocators who are able to ultimately dictate the research direction, grant allocators themselves may not have sufficient compute available as model runs continue to increase in size, and the process is one-off rather than ongoing. Ideologically it is almost antithetical to the permissionless innovation that typically characterizes open source, since approval of established bureaucratic entities is required.
Significantly more appealing, and closest to the true spirit of opensource, is collaborative training across individually controlled accelerators, where individuals contribute their compute in addition to their time. There are two main obstacles to this. The first is that decentralized training is largely considered to be technically infeasible. We address this argument in our previous article. The second is assembling sufficient compute. A volunteer network will likely never reach the scale required for trillion parameter model runs due to the cost of training being a tangible cost to participants, with no way of recouping this cost. Hence, resolving the technical challenges of decentralized training (training via low-bandwidth node-to-node interconnects, among other problems) is only one part of a larger research agenda that must be pursued for the practical realization of decentralized foundation models, with correct incentivization being the other major component.
Traditional fiat and fixed rates won’t work
The simplest form of incentivisation is to pay compute providers with traditional monetary compensation. This has several practical and philosophical issues that make it infeasible and unappealing. Consider a model designer who specifies a model run and then recruits trainers into a training protocol where they are compensated at a fixed rate per verified FLOP. By fixed rate we refer to any setting where payment is made on the basis of computation contribution in a form of value external to the model itself.
Large pools of initial capital must be assembled by the model designers. This reverts to similar dynamics to the centralized or grant-funded case and heavily restricts the pool of participants who can influence model design. In this case, the benefit of doing a decentralized run at all is not clear unless it can be made cheaper than the centralized compute alternative.
Cross-jurisdiction payments are slow and expensive. Compute nodes will be geographically separated. Traditional financial infrastructure does not support micropayments across geographic borders. Hence, as nodes are constantly entering and exiting the network , payments would need to be tracked, accumulated and batched, removing the ability for real-time value accrual. In addition, given that the protocol learning is effectively self contained with no other dependence on financial infrastructure, it is enough of a reason to avoid traditional payment mechanisms given fees would be non-trivial in a case where a high volume of low-value transactions is required. Such fees also disproportionately disadvantage small actors who may wish to contribute a personal compute budget where fixed fees will overwhelm their training contribution.
Accessibility is reduced. Loss of guaranteed access to models which should be a fundamental public good with guaranteed access. Not requiring access to traditional financial infrastructure is a major benefit – all that is required is an internet connection.
Incentive mismatch between model designers and computer providers. If payment is on a per-FLOP basis, computational contributors have no interest in the quality of the final model. They are incentivized to contribute bad or random gradients that may pass verification but damage the model. The expected burden on the protocol to verify computation is higher, which in turn introduces larger overhead.
Partial model ownership will work
Ideal alignment is achieved when the model is designed and owned by the trainers, downstream use is paid at a rate decided by a competitive market, and all model revenue returns programmatically to the trainers. Trainers are not only less incentivized to try and submit bad work (as they would get ownership of a worse or even useless model – although others may still try to derail other coalitions training runs) – but also become model advocates as their return is directly tied to final model use. That is, the higher utility a model is, in terms of downstream paying users, the higher the return of the model trainers.
Model designers contribute more than simply compute. Furthermore, compute providers take more risk early in training as model performance is not clear. These two properties can be combined by allocating ownership not only per verified-FLOP, but by risk-adjusted compute contribution and allowing model designers an exclusivity to the early training period. This has the advantage as while model designers do not require a large capital pool, they are required to make some compute investment at the start of a run in order to ‘earn’ their ownership stake. This discourages low-conviction training runs. There are many ways to quantify ‘risk-adjusted’ computation contribution; a simple example is to allocate proportional to the model loss during training which typically drops very sharply during early training.
One way to view Protocol Learning is as a protocol that defines a meta-objective for participants of maximum utility model development. If a trainer can contribute their computational resources to a model that is likely to have higher rates of use, they should. Training useless models becomes pointless within Protocol Learning.
Incentivizing via partial ownership results in numerous benefits and removes many of the problems caused by fixed rate incentives;
No capital requirement for model designers to initiate a run. Payment is via fractional ownership of the model. Before the model is trained this ownership is worthless, only grows as the run progresses, and is allocated proportional to contribution. Model designers hence do not need to accumulate a large pool of capital to train a model, they only need to be convincing to compute providers (that the compute provider's computational contribution will be worth more than its cost).
Market dynamics at the model design level. By allocating fractional ownership rather than a fixed rate per FLOP, model trainers contribute more than simply computational cycles, they contribute judgment toward which model will be maximally useful. This introduces similar dynamics to a prediction market, but in the case where the ‘bet’ (purchased with compute) is which model or class of models would be maximally useful to downstream users. Individuals hence must have value in the protocol beyond simply controlling compute. This judgment does not need to be via a detailed technical understanding of model training, it may come from insight into human behaviour or of a specific industry or domain where one model may not be obviously useful to the broader pool of model trainers.
Value alignment. Trainers are only incentivized to make models that are useful; if there is no downstream use they will not recoup the cost of training.
Trainers are model advocates and model hosters; as payoff is proportional to model uptake, trainers are incentivized to serve the models, and to drive model use after training so that they can recoup the cost of training from model users.
Facilitates a portfolio of model training risk. Some training runs are highly speculative but may result in large payoffs (for example a novel architecture). Others are low risk but capped in their upside (for example replicating a known recipe with variants to the datamix). Fractional ownership allows trainers and participants to have exposure to the outcome of many such runs simultaneously. In the centralized case this dispersion of risk can only be achieved by the centralized entity completing all training runs itself - at massive cost.
Most importantly, fractional ownership results in value flow that is self-contained. Useful models are created inside the protocol, and ownership is allocated within the protocol. Contributors are able to contribute and be compensated with the sole requirement being access to an internet connection and a device that can perform computation. This is clearly appealing, and the question becomes how, or if, such a system can be implemented in practice.
Protocol Models implement fractional ownership
If model weights are public, local inference can be set up, variants can be proliferated, and the value that was created during training becomes dispersed and no longer held by the trainers. Consequently in the centralized case the value accrual is straightforward; keep the weights private, allow use via paid black-box API and implement anti-distillation measures both programmatically and via usage licenses.
There is no equivalent mechanism to ensure value flow to trainers in the decentralized case. Protocol Models (PMs) are an approach to implementing this dynamic. The core property of PMs is that they are trainable, but unextractable from the swarm and at no point can any node, or group of nodes, extract a usable version of the model from the swarm, without spending more compute power than would be required to train the model. This is because for value flow to be enforced, the full weight set must remain unobtainable to any subset of participants in the swarm. However, for any utility to actually be created, the model must also be able to be trained.
Protocol Models facilitate fractional ownership by allowing inference only with the presence of a credential that is allocated during training. Because inference cannot be performed within the swarm without a valid credential and the model can never leave the swarm, ownership of the credential directly translates to fractional ownership of the model. Credentials are single use; they can be bought and sold but on use are absorbed by the swarm and a new credential allocated back to the trainers, who may sell this again.
It may not be clear how unextractability is feasible. PMs exploit the fact that Neural Networks are highly sequential and composed of operations which form a DAG when mapped by dependency; the computational graph. Consider a node holding an entire intermediate layer. This node does not require any other layer weights to perform its required forward or backward pass, only the intermediate activation, and gradients for the loss with respect to the layer's output. Hence, in the simplest case, unextractable models are feasible during inference with a trusted authority that could allocate the trained layers and addresses of the previous and next node to the various participants. The challenge is: can such a setup be maintained during training, and in a fully decentralized manner.
PMs are a novel concept. The ratio of model size to node capacity will be important as it dictates the fraction of a model any given node may access, and it is likely PMs will only be possible with large models. Clearly, model replication training methods (DDP-like setups, as is common in the Federated Learning literature) are not compatible here as every node has access to the full weights, and hence a single bad actor would extract the model. Model extraction in the PL setting can be thought of as a more complex variant of the model distillation problem where partial weight shards may also be obtained by the adversary. How can this be prevented and which sharding strategies make extraction most difficult are all problems that the research will need to address.
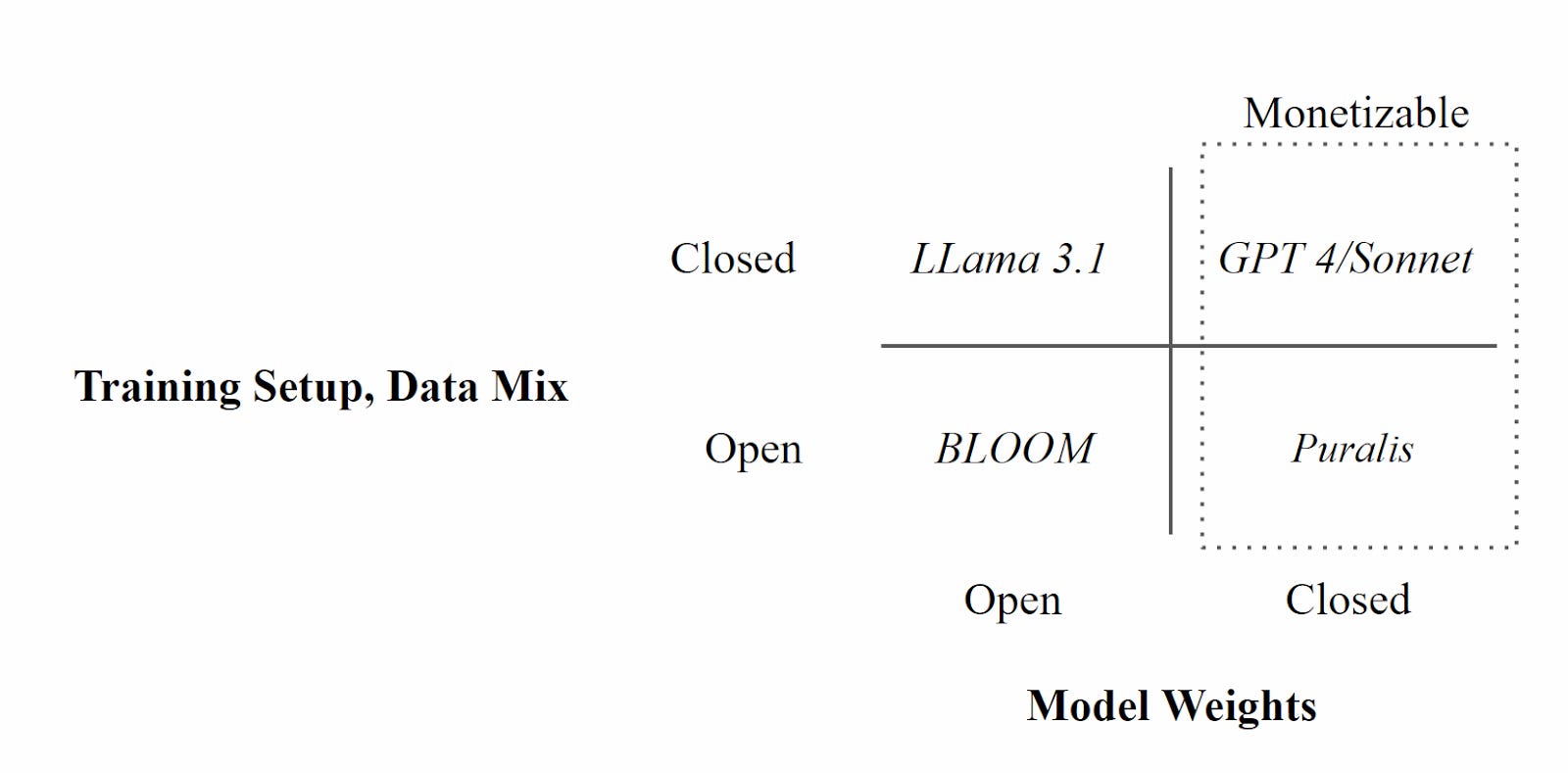
A reasonable response to the PL setup is that not being able to extract full model weights means such models are not opensource - we view ‘openness of setup’ to be considerably more critical to interpreting model behaviour than access to the weights, given that it prevents poisoned model risk. We emphasize again that with open weights it is very hard to see how such models may be monetized, and hence sufficient compute assembled to carry out the very large training runs required.
Incentives beget verification
When training moves from the volunteer or centralized setting a problem arises when any form of value is transferred in exchange for model training operation. Nodes can submit random gradients, which are much cheaper to compute, and potentially receive the same payment. There will also be actors that will seek to disrupt training regardless of cost. Hence, if training is incentivized it must also be trustless; the protocol must implement a method that detects bad computations, as well as preventing them from derailing the training run.
There has been significant work on compute verification in the cryptographic community, and emerging work in the AI literature where it is broadly categorized under the term “Proof of Learning”. We will discuss verification in later articles, however it is interesting to note a unique property of neural networks here; all computations in a training run are not required to be accurate for a model of exactly the same utility to be produced. In fact, many regularization techniques (dropout, stochastic depth, label smoothing etc.) purposefully distort with randomness during training in order to improve generalization. There are very few other systems that have this property. Up to a limit, individual computations can be ‘wrong’ (in the sense of having low/no information content), and have no effect on the final produced model, and in some cases may even help.
Conclusion
Protocol Learning is the first framework that proposes combining open collaboration with value capture by ensuring that models can be trained collaboratively while remaining unobtainable by any single actor outside the swarm. This provides an avenue to compute abundance at the opensource foundation model layer and creates a foothold for true distributed ownership and governance of such models. The realization of Protocol Learning will require the convergence of cryptography and AI, which as of yet have remained relatively disjoint. There is real research work that remains, however the prize is enormous; the largest models to ever be trained, an alternative to the massive concentration of power that is emerging, and permissionless innovation dynamics at the foundation model layer.
